The International Conference on Computer Vision and Pattern Recognition (CVPR 2025)was held in Nashville, Tennessee, USA from June 11th to 15th, 2025. The conference is the top conference in the field of computer vision and pattern recognition organized by the Institute of Electrical and Electronics Engineers (IEEE), and is recommended as an A-class international academic conference by the Chinese Computer Society (CCF). It ranks second in the global academic publication list on the Google Scholar index, second only to Nature. The CVPR 2025 held this year received a total of 13,008 valid submissions, of which 2,878 were accepted, with an acceptance rate of 22.1%.
In the recently released CVPR 2025 admission results, multiple latest research achievements from faculties and students of the School of Computer Science and Engineering at Tianjin University of Technology have been selected. The relevant brief introduction is as follows:
1.Customized Condition Controllable Generation for Video Soundtrack[1]
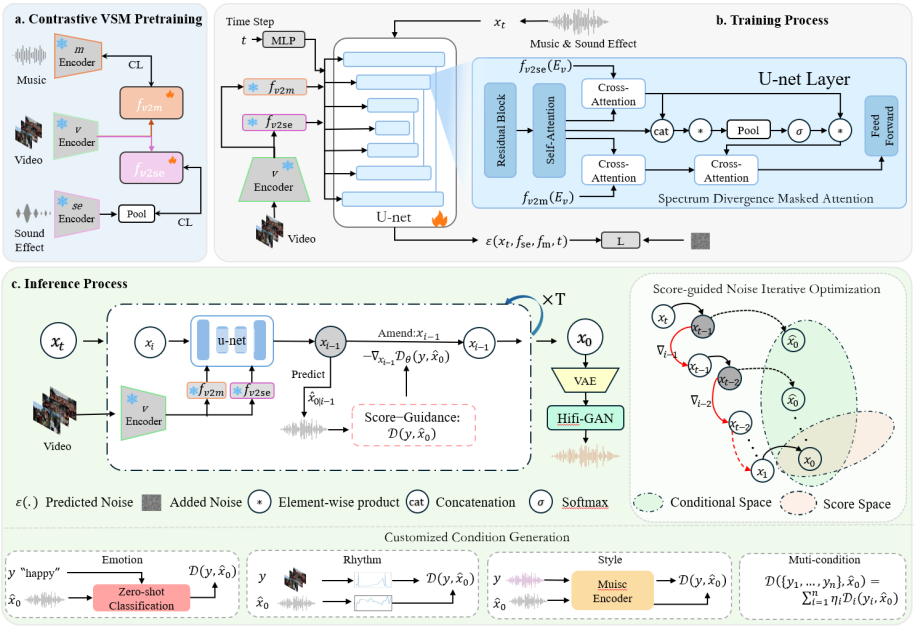
This paper is written by Associate Professor Fan Qi and her 2023 master's student Kunsheng Ma. This study conducts in-depth research on music and sound effects in the field of video music generation, and proposes an innovative video music diffusion model framework that utilizes spectral divergence mask attention and guided noise optimization. This framework integrates three core modules: visual sound music pre-training, spectral divergence mask attention mechanism and score guided noise iterative optimization, effectively mapping the modal information of music and sound effects to a unified feature space. Through this mechanism, the model significantly enhances its ability to capture complex audio dynamics while maintaining the unique characteristics of sound effects and music. In addition, even under the conditions of optimizing video music and without complex learning and training of video information, this method can still provide music creators with highly customizable control capabilities, making the music generation process more flexible and efficient.
2.Language Guided Concept Bottleneck Models for Interpretable Continual Learning[2]
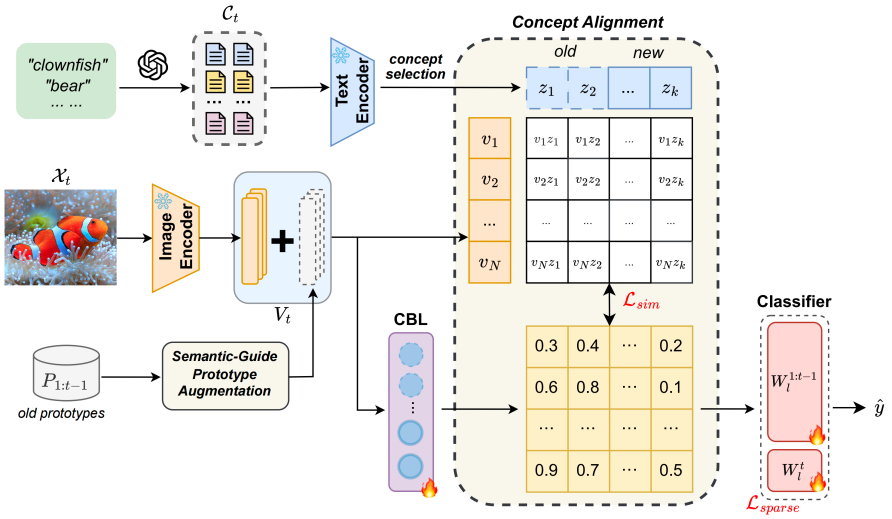
This paper is written by Associate Professor Lu Yu and HaoyuHan, a 2023 master's student under her guidance. The goal of continuous learning is to enable the learning system to continuously acquire new knowledge while not forgetting previously learned information. The ongoing challenge lies in mitigating catastrophic forgetting while maintaining interpretability across tasks. Most existing continuous methods mainly focus on retaining learned knowledge to improve model performance. However, with the introduction of new information, the interpretability of the learning process is crucial for understanding the constantly evolving decision-making mechanisms, but this direction has rarely been explored. This study proposes a novel framework that integrates language guided Concept Bottleneck Models (CBMs) to simultaneously address these two challenges. Our method utilizes a Concept Bottleneck Layer to align semantic consistency with the CLIP model, thereby learning concepts that are understandable to humans and can generalize across tasks. By focusing on interpretable concepts, this method not only enhances the model's ability to retain knowledge over time, but also provides transparent decision-making insights. We validated the effectiveness of our method on multiple datasets, with the final average accuracy on the ImageNet subset surpassing the existing optimal method by 3.06%. In addition, we further promote the understanding of interpretable continuous learning by visualizing the model's predictive basis through conceptual visualization.
3.SCSegamba: Lightweight Structure-Aware Vision Mamba for Crack Segmentation in Structures[3]
This paper is written by HuiLiu, a 2023 master's student under the guidance of Professor Fan Shi and Professor Xu Cheng, and the corresponding author is Dr. Chen Jia. This study proposes a lightweight structure aware visual Mamba network SCSegamba optimized for edge devices, which achieves high-precision crack segmentation in complex scenes through dynamic feature modeling mechanism and minimalist and efficient design. The core innovation lies in the design of a lightweight gated bottleneck convolution based on low rank decomposition and dynamic gating mechanism. Compared with standard convolution, low rank decomposition reduces the parameter size and GFLOPs of the network by 64.60% and 71.63%, respectively, while significantly reducing computational requirements and maintaining the ability to extract crack morphology features; The structure aware state space module utilizes an innovative multi-path structure aware scanning strategy to perceive the topological adjacency relationships between crack pixels, improving the semantic continuity of feature maps. Compared with traditional parallel scanning strategies, it improves F1 and mIoU by 1.19% and 0.84%, respectively; In addition, the lightweight multi-scale feature segmentation head can generate high-quality segmentation images that effectively suppress background noise with an extremely low parameter size of 0.01M and a computational requirement of 0.42GFLOPs. The overall parameter size of this network model is only 2.80M and 18.16GFLOPs, especially compared with the method based on lightweight Transformer, the parameter size has been reduced by 52.54%. On the structural crack detection dataset containing challenging scenes such as low contrast, multiple lighting conditions and complex background noise, the F1 score and mIoU index of the network reach 0.8390 and 0.8479 respectively, which are 2.22% and 1.74% higher than the second best method, respectively, showing the optimal performance, providing a feasible lightweight solution for real-time structural crack detection on edge computing devices.

The School of Computer Science and Engineering at Tianjin University of Technology has always adhered to the guidance of national strategic needs, driven by intelligent technology innovation, and continuously cultivated cutting-edge fields such as artificial intelligence and computer vision. The inclusion of multiple achievements in CVPR 2025 marks a new breakthrough in our research in artificial intelligence, computer vision and interdisciplinary fields. Looking towards the future, we will further focus on the strategic needs of national artificial intelligence and digital economy, and explore interdisciplinary integration and innovation. The college will also continue to optimize its talent cultivation system, relying on high-level scientific research projects to cultivate composite talents with both international perspectives and engineering practical abilities, and contribute Chinese wisdom to global scientific and technological development.
[1] Fan Qi, Kunsheng Ma, Changsheng Xu. Customized Condition Controllable Generation for Video Soundtrack. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), 2025.
[2] Lu Yu, Haoyu Han, Zhe Tao, Hantao Yao, Changsheng Xu. Language Guided Concept Bottleneck Models for Interpretable Continual Learning. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), 2025.
[3] Hui Liu, Chen Jia, Fan Shi, Xu Cheng, Shengyong Chen. SCSegamba: Lightweight Structure-Aware Vision Mamba for Crack Segmentation in Structures. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), 2025.
