The AAAI Conference on Artificial Intelligence (AAAI) is a premier international venue in the field of artificial intelligence and is listed as a CCF Class-A recommended conference. AAAI 2026 will be held from January 20 to 27, 2026, in Singapore. This year, a total of 23,680 papers were submitted, with 4,167 papers accepted, resulting in an acceptance rate of 17.6%. The School of Computer Science has had four papers accepted to AAAI 2026, covering topics such as text-to-image generation, image manipulation detection and time-series classification. A brief introduction to the accepted papers is provided below:
Paper 1
Title:ViType: High-Fidelity Visual Text Rendering via Glyph-Aware Multimodal Diffusion
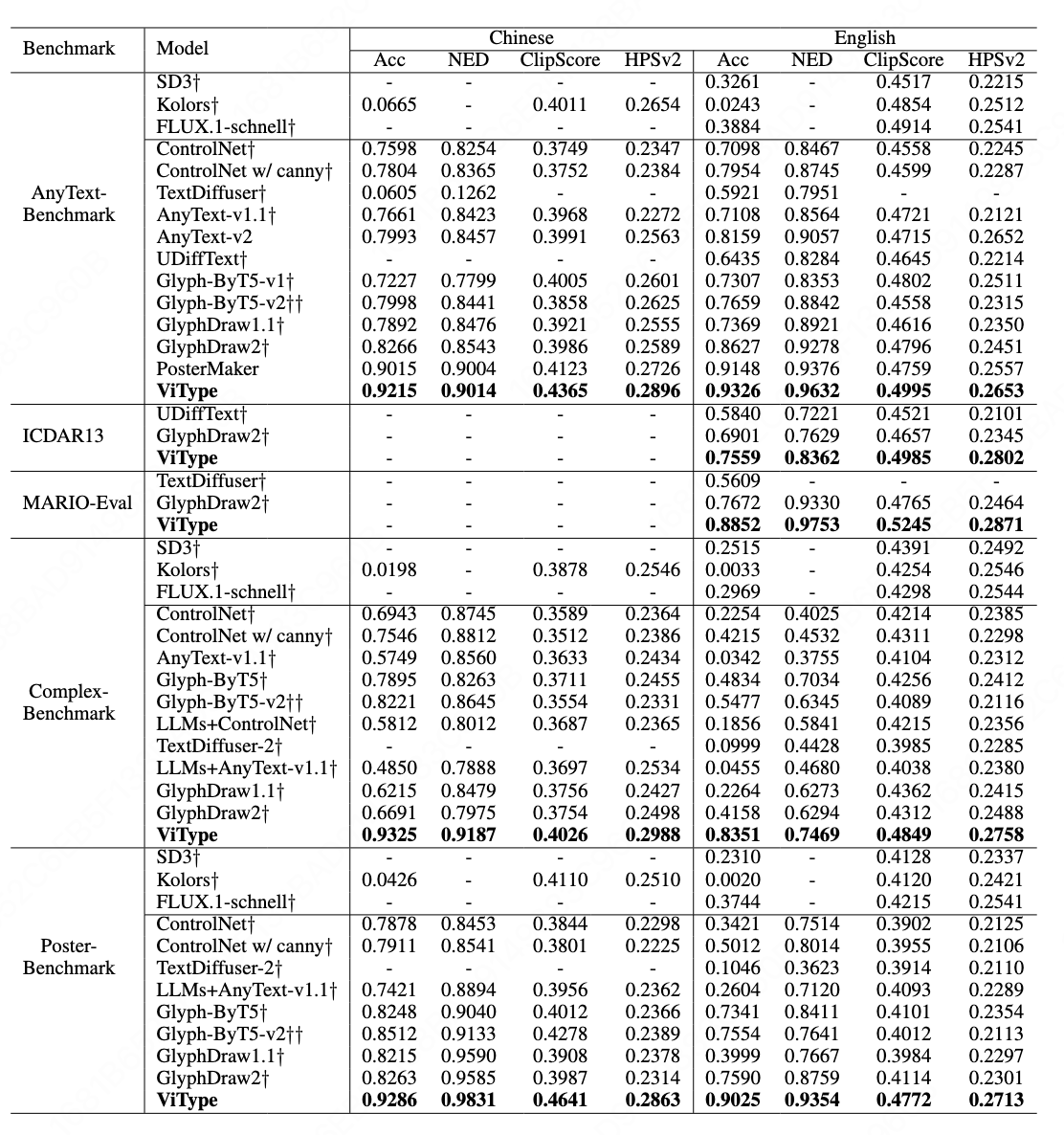
Summary: Current mainstream text-to-image (T2I) models still face three major challenges in visual text rendering: Lack of glyph-level understanding: Text encoders such as CLIP and T5 cannot perceive detailed character shapes and structures. Semantic–glyph confusion: Models often conflate “text to be rendered” with general semantic descriptions. Limited aesthetic quality: Generated images frequently suffer from poor integration of text with the background in terms of color, lighting and perspective.
To address these issues, the paper introduces ViType, a glyph-aware multimodal diffusion framework. It is the first to incorporate a VQA-style glyph–text alignment mechanism into diffusion models. With a three-stage “recognize–render–refine” training strategy, ViType enables diffusion models to render arbitrary text in a high-fidelity, multilingual and stylized manner, achieving new state-of-the-art results across five major benchmarks.The primary innovations of ViType include: 1) Text–glyph alignment: A VQA-inspired mechanism aligns character images with their attribute descriptions within the embedding space, enhancing the model’s ability to capture glyph-level visual characteristics. 2) Multimodal joint rendering: Using the MMDiT architecture, ViType jointly fuses glyph visual embeddings with semantic text tokens, ensuring cross-modal consistency and producing structurally accurate, stylistically coherent text rendering. 3) Aesthetic-enhanced training: A large-scale, multi-source dataset of over 20 million high-quality text–image pairs is constructed to improve text–background integration, significantly enhancing the overall visual aesthetics and layout quality of the generated images.
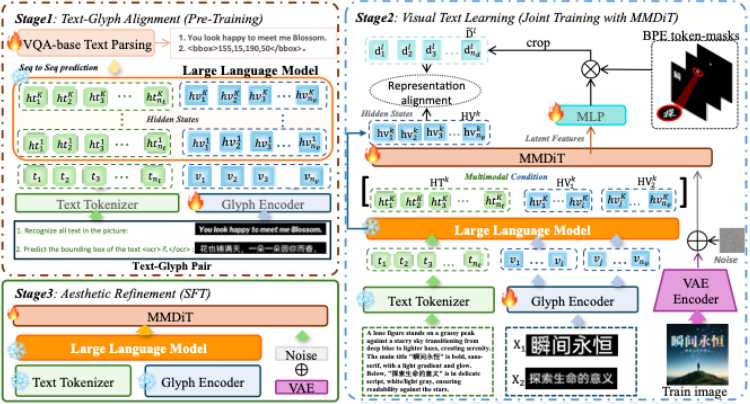

The first author of this paper is Lishuai Gao, a Ph.D. candidate at the School of Computer Science, Tianjin University of Technology. The work was supervised by Professor Zan Gao, and jointly guided by Jun-Yan He, Yingsen Zeng, Jie Hu, Xiaopeng Sun, Yujie Zhong,and Xiaoming Wei. The paper has been accepted as an Oral presentation.
Paper 2
Title:Amplifying Discrepancies: Exploiting Macro and Micro Inconsistencies for Image Manipulation Localization
Summary:In response to increasingly sophisticated image forgery techniques, recent studies have explored various perspectives—such as noise patterns, frequency-domain cues and multi-scale edges—or combined contrastive learning with prior knowledge to develop high-performance detection models. However, existing methods have not fully exploited the inherent multi-level discrepancies between manipulated regions and authentic regions. To address this gap, the paper proposes FRD-Net (Focus Region Discrepancy Network).
FRD-Net explicitly mines and amplifies the intrinsic inconsistencies between tampered and authentic areas in a task-driven manner. By jointly modeling discrepancies at both macro and micro levels, the approach transforms manipulation localization from traditional “anomaly feature detection” into a more principled “real–fake discrepancy comparison,” enabling precise localization and strong robustness across diverse manipulation scenarios.To implement this idea, FRD-Net introduces an efficient and lightweight Focus Region Discrepancy Block (FRD Block), which consists of two key components:Iterative Clustering Module (ICM):This module dynamically clusters feature representations to form two adaptive cluster centers corresponding to “suspicious regions” and “authentic background”.Through iterative updates, the semantic separation between these centers is progressively enhanced, allowing the model to automatically emphasize object-level macro discrepancies in the high-dimensional feature space.Differential Progressive Module (DPM):Operating at the local level, DPM incorporates angular and central differential convolutions to progressively amplify fine-grained artifacts—such as texture discontinuities and broken edges—thereby capturing micro-structural inconsistencies with high precision.The macro-level ICM provides global semantic priors for the micro-level DPM, while the DPM in turn refines region boundaries, forming a tightly coupled discrepancy amplification mechanism.Extensive experiments on multiple publicly available image manipulation localization benchmarks demonstrate that FRD-Net significantly outperforms mainstream methods in accuracy, boundary quality and robustness, while maintaining a lightweight architecture and low computational cost. This highlights its strong potential for real-world deployment. The proposed framework introduces a new discrepancy modeling paradigm for image manipulation localization and offers fresh insights for multimedia forensics by emphasizing the exploitation of intrinsic inconsistencies between authentic and manipulated regions.
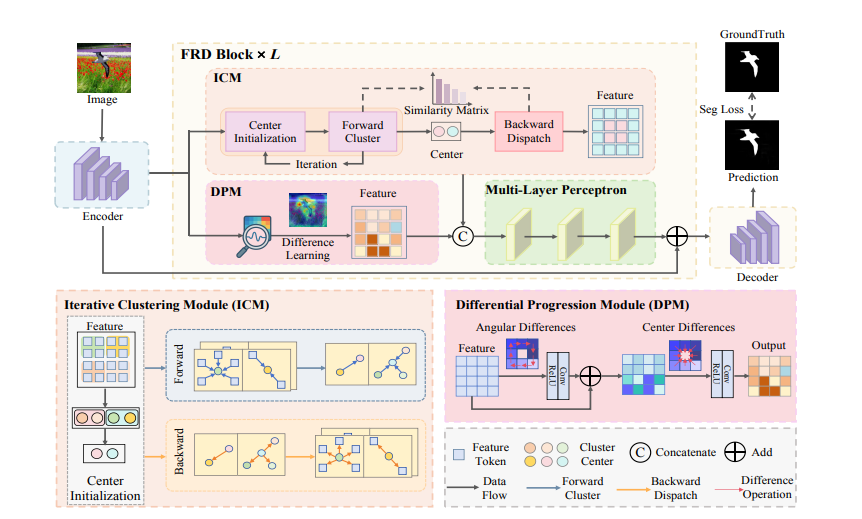
The first author of this work is Shenghao Chen,a Ph.D. candidate at the School of Computer Science, Tianjin University of Technology. The research was supervised by Professor Zan Gao, with additional guidance from Yibo Zhao, Tianyi Wang, Chunjie Ma, Weili Guan, and Ming Li. The paper has been accepted as a Poster presentation.
Paper 3
Title:Duplex Rewards Optimization for Test-Time Composed Image Retrieval
Summary:Composed Image Retrieval (CIR) aims to retrieve a target image by combining a reference image with a modifying text description. In recent years, Zero-Shot CIR has gained increasing attention because it avoids the need for manually annotated triplet data. However, this paradigm inevitably requires additional training corpora, storage and computational resources, which limits its practicality. Inspired by advances in Test-Time Adaptation (TTA), this study introduces a Test-Time CIR (TT-CIR) paradigm that enables models to effectively adapt to and accurately retrieve test samples while reducing computational overhead.The study identifies two key limitations in current reward-based TTA approaches:1)Restricted reward pools, which hinder exploration of semantically relevant candidate rewards;2)Conservative knowledge feedback, which suppresses the adaptability of reward signals to the test-time data distribution.
To address these challenges, this work proposes a test-time reinforcement learning framework based on Duplex Rewards Optimization, integrating two novel components: Counterfactual-guided Multinomial Sampling (CMS) and Duplex Rewards Modeling (DRM). CMS explores candidate reward pools that are semantically aligned with the query, effectively uncovering informative reward signals. DRM generates stable and highly adaptive duplex rewards that guide the model to align with the current test data.Experiments on mainstream CIR benchmarks show that the proposed method outperforms existing approaches in both retrieval accuracy and efficiency, advancing the practical deployment of CIR models in real-world applications.
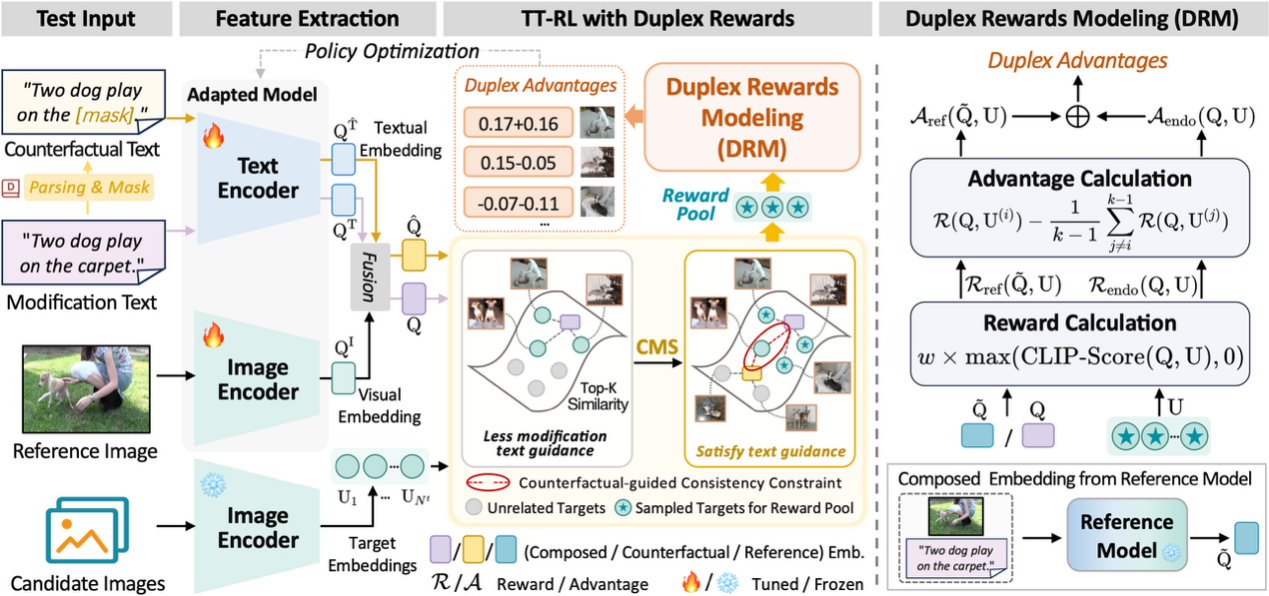
The first author of this paper is Haoliang Zhou, a Ph.D. candidate at the School of Computer Science, Tianjin University of Technology. The work was supervised by Professor Feifei Zhang, with additional guidance from Changsheng Xu.
Paper 4
Title:Beyond Missing Data Imputation: Information-Theoretic Coupling of Missingness and Class Imbalance for Optimal Irregular Time Series Classification
Summary:Irregular sampling and structured missingness are pervasive in real-world time series. Existing research on irregular time series largely relies on imputation models, masking mechanisms, frequency-domain enhancement, or attention architectures to mitigate representation degradation caused by missing data. However, most methods treat missingness as independent noise, overlooking a core empirical principle widely observed in real-world datasets: there exists significant mutual information between missingness patterns and class label (I(M; Y) > 0).This coupling is especially prominent in highly imbalanced scenarios, where minority classes often exhibit higher missingness density and more severe spectral distortion, leading to systematic suppression of discriminative features.
Building on this theoretical insight, the paper proposes SPECTRA, a framework that redefines irregular time series classification through the lens of missingness–imbalance coupling, aiming to achieve interpretable, generalizable and robust representations.Under a unified task-driven design, SPECTRA introduces three synergistic modules:Missingness-Aware Frequency Filtering(MAFF)Module– Corrects spectral leakage and frequency distortion induced by missingness, restoring multi-scale temporal dependencies;Missingness Pattern Encoder(MPE)Module– Explicitly encodes continuous and intermittent missingness and their temporal structures, treating missingness itself as a discriminative prior within the high-dimensional embedding space;Category-Guided Feature Refinement (CGFR)Module – Based on information geometry, enforces intra-class manifold alignment and enlarges inter-class boundaries, enabling stable discrimination even under extreme imbalance.Extensive experiments on multiple irregular time series benchmarks demonstrate that SPECTRA substantially outperforms state-of-the-art models and maintains strong robustness under high missingness rates, severe imbalance, and sensor failures. These results highlight a new paradigm for time series classification driven by structured missingness modeling.
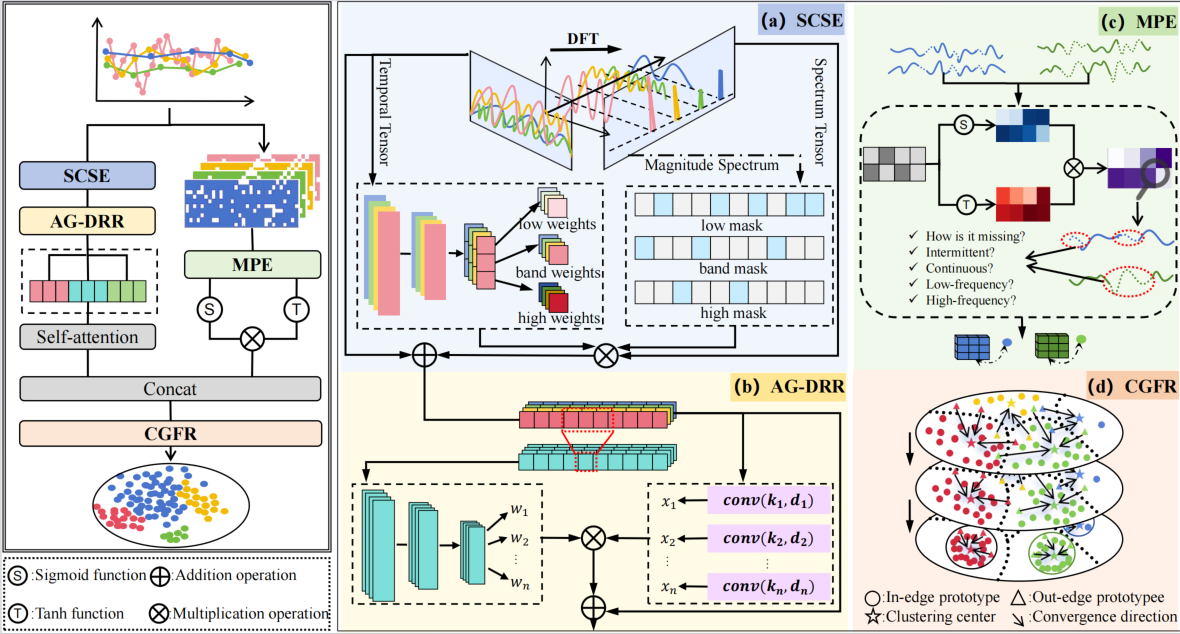
The first author of this work is Xin Qin, a Ph.D. candidate at the School of Computer Science, Tianjin University of Technology. The research was supervised by Professor Xu Cheng, with additional guidance from Mengna Liu, Wenjie Wang, Tianjiao Li, and Xiufeng Liu.The paper has been accepted as an Oral presentation.
